
Infinity v0.2 delivers the most comprehensive hybrid search solution to date, including vector search, full-text search, sparse vector search, and tensor search. It also provides three fusion reranking methods: RRF, Weighted Sum, and ColBERT Reranker. How effective are these search and ranking solutions in practice? This blog article delves into the details for you.
We employed the Multilingual Long-Document Retrieval (MLDR) dataset in our benchmark evaluations. MLDR is part of MTEB's benchmark datasets for measuring the performance of embedding models [reference 1], including 200,000 long documents. We also utilized BGE-M3 [reference 2] as the embedding model, for its ability to generate both dense and sparse vectors. The evaluation script is available in Infinity's GitHub repository [reference 3].
Evaluation 1: We converted 200,000 MLDR documents into dense and sparse vectors using BGE-M3, then inserted them into the Infinity database. The database comprises three columns—original text, dense vectors, and sparse vectors—each with its corresponding index built (full-text, vector, and sparse vector). This benchmark employs a hybrid search using RRF for reranking, with nDCG@10 as the evaluation metric. Additional parameters include Top N = 1,000 and 800 queries, each with an average length of 10 tokens.
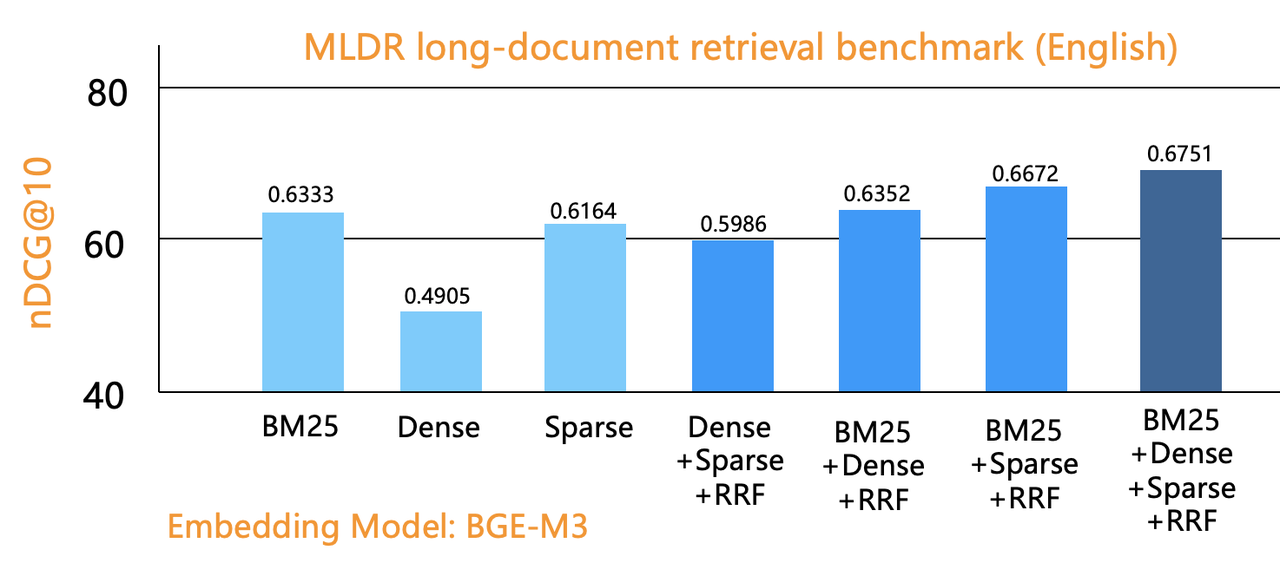
The results indicate that three-way retrievals perform best, followed by the two-way approaches, with one-way retrieval performing worst. This aligns with IBM Research's Blended RAG study [reference 4]. Contrary to BGE-M3's paper [reference 2], which suggests BM25 and dense vectors have comparably low retrieval quality, our evaluation ranked BM25 full-text search highest. After examining the evaluation code, we found that BGE-M3 used a basic BM25 implementation rather than a database with innate support for the standard BM25 algorithm, explaining the discrepancy. In practice, an effective BM25 implementation for RAG requires more than TF/IDF statistical scoring; it needs a comprehensive Top K Union semantic, where each token match should contribute to the score.
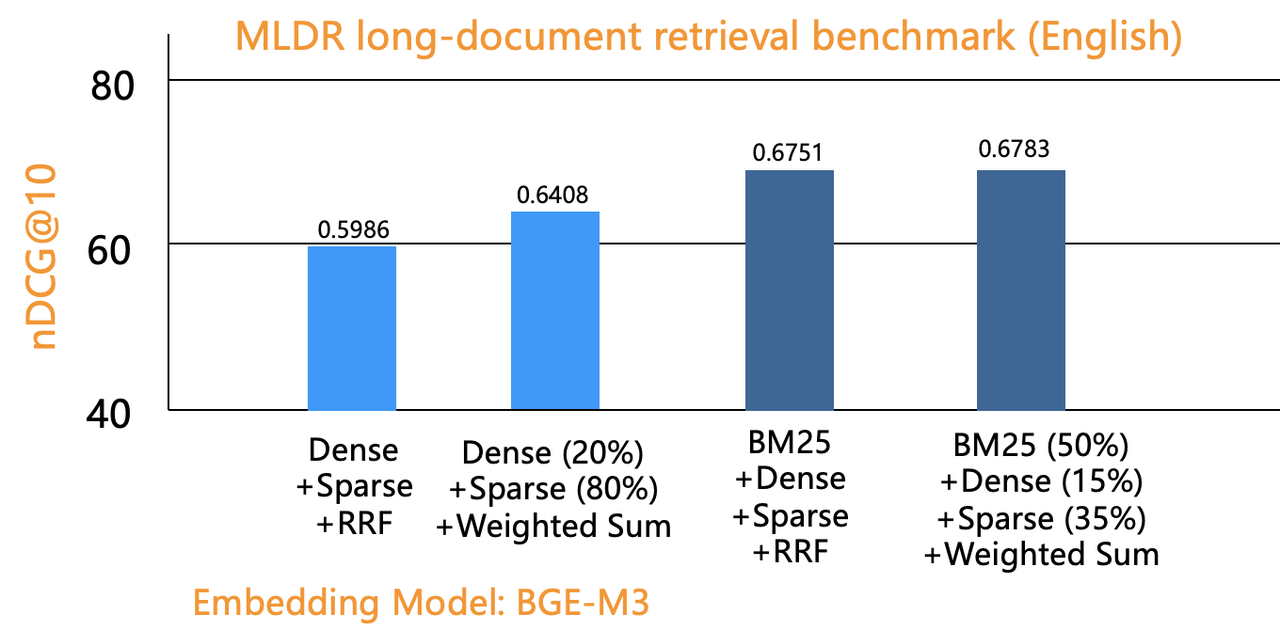
Evaluation 2 is similar, but it employs Weighted Sum for fused ranking to compare with RRF. Weighted Sum allows users to specify weights for each retrieval path. As shown below, a two-way retrieval using 20% weighted dense vector and 80% weighted sparse vector significantly outperformed RRF reranking in nDGC gains. However, the difference between Weighted Sum and RRF reranking was negligible on three-way retrieval regardless of our optimization attempts. In essence, while Weighted Sum offers users more options, its ranking quality is not fundamentally different from RRF.
Evaluation 3 adds a column to the Infinity database to store tensors generated using Jina-ColBERT [reference 7]. The evaluation compares the nDCG gains of ColBERT reranking with those of one-way retrievals and RRF-based hybrid searches.
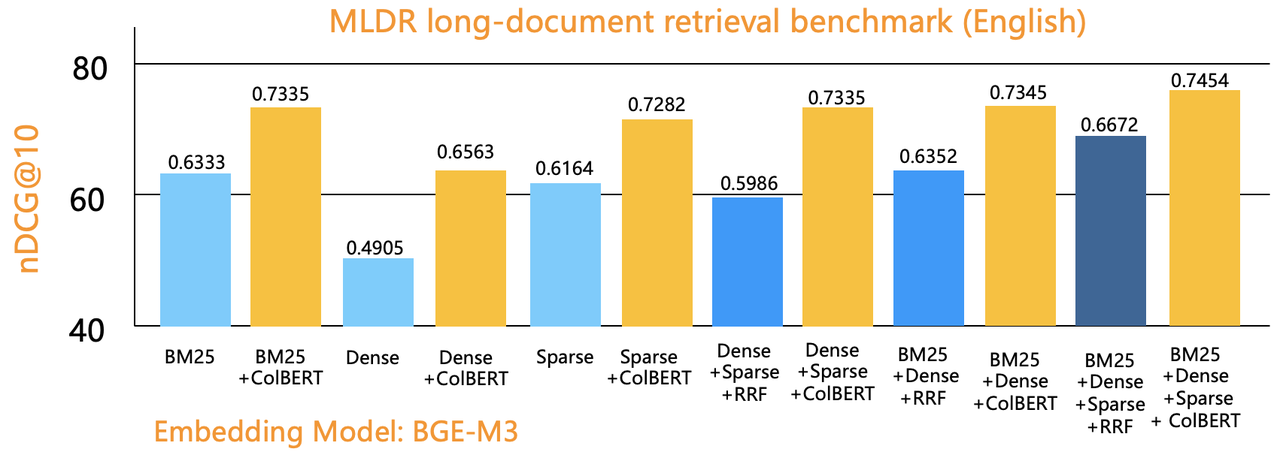
The graph above shows that the nDCG gains of all retrieval methods improved significantly after integrating the tensor-based ColBERT Reranker. ColBERT, a Late Interaction model, offers comparable reranking quality to top performers on the MTEB Reranker leaderboard, but with 100 times better performance, allowing for reranking over a larger range. The presented results are for reranking the top 100 results. Reranking the top 1,000 did not contribute notably to nDCG gains but suffer significant performance deterioration, thus not recommended. It typically incurs seconds of delay to rerank top 20 results with traditional rerankers, which operate outside of the database, and this is even with GPU inference acceleration. By integrating an in-house, high-performance ColBERT reranker, the Infinity database can expand its retrieval scope to the top 100 or even 1,000 results without significantly impacting query latency. Moreover, Infinity with the ColBERT reranker can run solely on a CPU architecture, substantially reducing deployment costs.
Evaluation 4 uses tensors for ranking rather than reranking. The Infinity database makes it possible to use tensors as either reranker or a separate retrieval option. To achieve this, Infinity has implemented an in-house EMVB index, which can be seen as a performance-enhanced version of ColBERTv2 [reference 5]. With this feature, users no longer need tools like RAGatouille [reference 6] and can implement ColBERT ranking functionality using Infinity end to end.
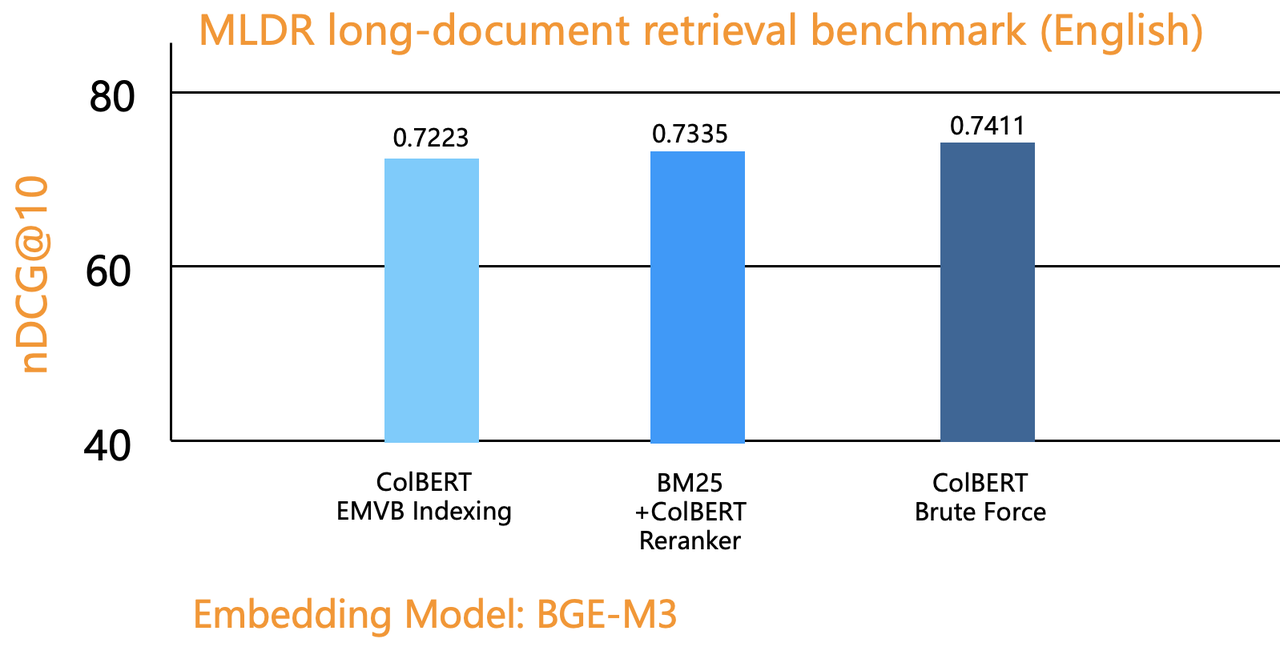
Evaluation 4 assesses ColBERT as both ranker and reranker, evaluating the nDCG gains of ColBERT ranker with both EMVB indexing and brute-force search. Results show that ColBERT ranker, even with brute-force search, doesn't significantly outperform ColBERT reranker, and that ColBERT ranker with EMVB indexing even yields lower ranking quality than ColBERT reranker.
Query time for ColBERT ranker is considerably longer than ColBERT reranker. The MLDR dataset contains 200,000 documents, approximately 2GB in size. When converted to tensors using Jina-ColBERT, its size expands to 320GB. This expansion occurs because tensors store vectors for every token in a document. With ColBERT's 128-dimensional model, the data volume increases by two orders of magnitude. Even with EMVB indexing, it would take an average of seven seconds to query data of this volume, without yielding better results.
As demonstrated by the above evaluations, integrating three-way hybrid search (BM25 + vector + sparse vector) with a ColBERT reranker achieves the highest nDCG score. It is now clear that the current best hybrid search approach involves employing ColBERT reranking. Some may question whether it is worthwhile to expand the original dataset by two orders of magnitude by adding a separate tensor column. However, such concerns are largely unfounded. Firstly, Infinity offers binary quantization for tensors, reducing the data size to 1/32 of the original without affecting ranking results a lot. Secondly, from a user's perspective, trading more storage for significantly higher ranking quality and lower costs (no GPU required for ranking) remains worthwhile. Lastly, Late Interaction models with slightly lower ranking results but requiring significantly less storage are likely to emerge soon. As a data infrastructure, Infinity will remain transparent to these changes, leaving such trade-off choices to its users.
The above evaluations are based on Infinity's multi-way retrieval tests on the MLDR dataset. Results may vary on other datasets, but the overall conclusion remains the same: three-way hybrid search combined with Tensor-based reranking currently provides the highest quality search results. We invite you to follow, star Infinity on GitHub at https://github.com/infiniflow/infinity. Let's work together to build the world's best AI-native database!
Bibliography
- https://huggingface.co/mteb
- https://huggingface.co/BAAI/bge-m3
- https://github.com/infiniflow/infinity/tree/main/python/benchmark/mldr_benchmark
- Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers, https://arxiv.org/abs/2404.07220 , 2024
- Colbertv2: Effective and efficient retrieval via lightweight late interaction, arXiv:2112.01488, 2021.
- RAGatouille https://github.com/bclavie/RAGatouille
- https://huggingface.co/jinaai/jina-colbert-v1-en