
After extensive development, the AI-native database Infinity was officially open-sourced on December 21, 2023. Infinity is specifically designed to cater to large models and is primarily used for Retrieval Augmented Generation (RAG). In the future, the infrastructure layer of enterprise AI applications will only require an AI-native database combined with a large model (LLM currently, multimodal models in the future) to fully address the core needs of enterprise AI applications including Copilot, search, recommendations, and conversational AI. All types of enterprise data — documents, regular databases (OLTP and OLAP), APIs, logs, and unstructured data — can be integrated into a single AI-native database. The database feeds the business queries’ data to the large model, which generates the final results for specific applications.
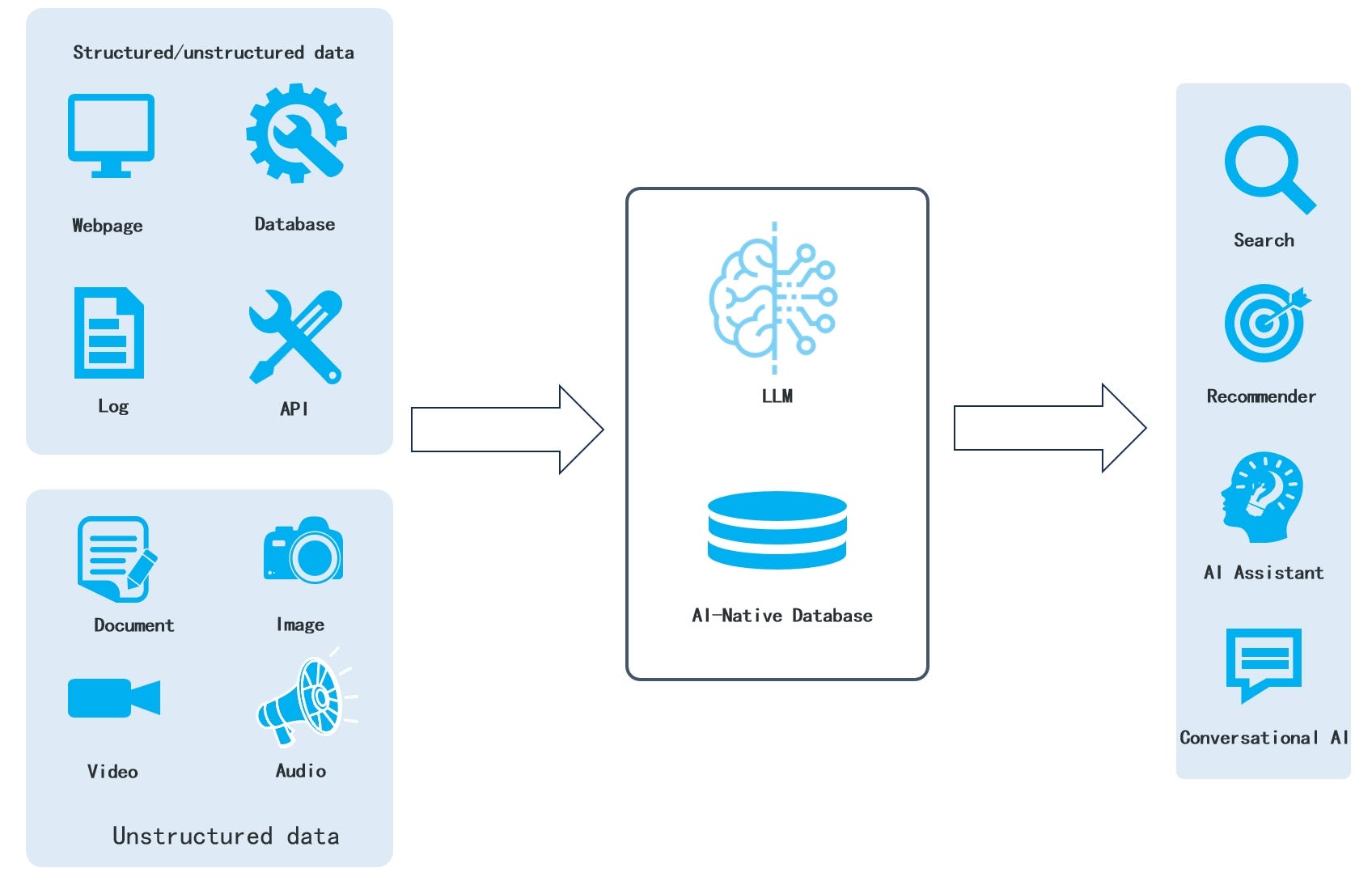
Vector databases alone are insufficient for enterprise AI applications
You might be wondering: What is an AI-native database? Is it just an old vector database with a new brand? Absolutely not! An AI-native database goes beyond a vector database. While vector databases are “necessary but not sufficient” infra for large language models. Why? Well, vectors are limited to semantic retrieval, and they are not suitable for the precise query required by enterprise AI applications.
For instance, consider the task of filtering content based on access permissions from an authorization table. This seemingly simple but common operation cannot be accomplished solely using vectors. Although some vector databases do support basic filtering and appear to work in similar scenarios, it’s important to note that this requires Extract-Transform-Load (ETL) to write permission fields to scalar fields in the vector database for effective filtering. This means three things:
- Introduces high-cost ETL for simple requirements.
- Updates to the raw data cannot be reflected in business.
- Introduces unnecessary data inflation. Permission filtering is just one example. Unnecessary data inflation becomes apparent when relying solely on ETL for handling diverse queries from multiple data sources. It’s akin to storing a wide table that includes all filtering fields within the vector database. This approach not only poses challenges in terms of system maintenance and data updates as mentioned above, but also results in unnecessary data inflation. Typically, it is only required to introduce wide tables in offline data lakes as part of enterprise system architecture.
For example, most RAG (Retrieval-Augmented Generation) applications require precise retrieval. For instance, when a user asks a question about the contents of a table within a PDF document, relying solely on vectors cannot provide accurate answers, resulting in hallucinations in the answers returned by LLM. Therefore, precise retrieval can only be achieved through search engines.
Therefore, the infrastructure for AI has actually evolved through three generations:
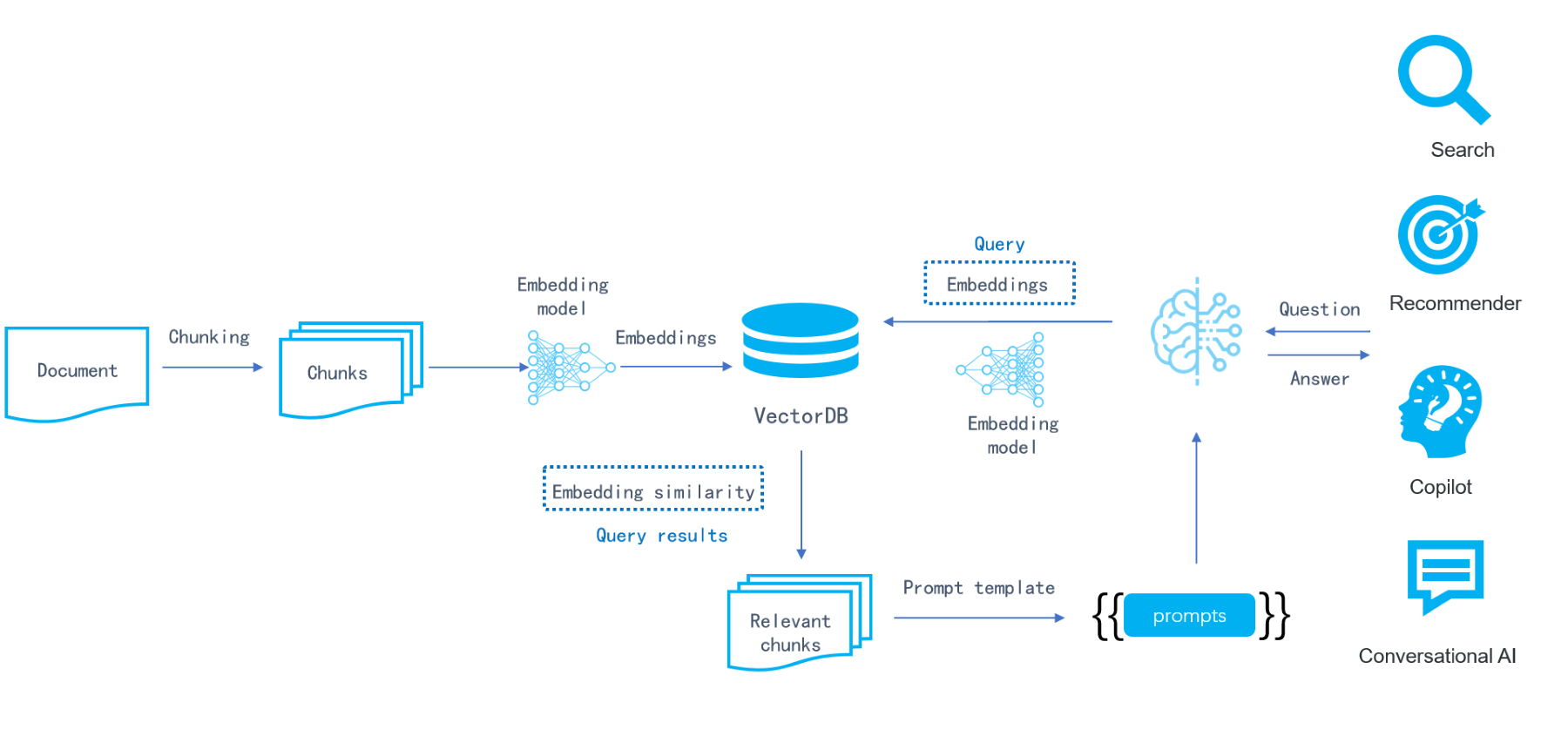
The initial phase of AI relies on data statistics and mining and features the search engine. Elasticsearch and databases like MySQL were commonly used as infrastructure supporting enterprise AI applications.
The next phase of AI brought deep learning, which led to vector search and the rise of vector databases. But because vector databases are only capable of vector search, they need to collaborate with various databases to create what is known as AI PaaS.
In the latest phase, with the arrival of large language models, numerous new opportunities have emerged. However, a vector database alone is insufficient to handle the demands of these scenarios. We now need an infrastructure that can perform vector search, full-text search, and structured data retrieval simultaneously. Additionally, it must support complex data retrieval for large language models and work in collaboration with them to fulfill the requirements of enterprise businesses.
AI-native database is not a traditional database or data lake plus vector plugins
You might find that PostgreSQL, a traditional relational database, has the pgvector plugin for vector search. However, you cannot directly create an AI-native database from these traditional databases with vector search. Let’s see if PostgreSQL can address the main problems in AI’s RAG applications. Once you have those answers, I think you’ll figure it out.
How to implement full-text search required by precise recall?
PostgreSQL is an OLTP (Online Transaction Processing) database that focuses on ensuring ACID compliance for data writes. It does not have any direct connection to vectors and full-text search. While PostgreSQL does offer support for full-text search and has been in existence for over a decade, enterprises tend to use Elasticsearch for full-text search rather than PostgreSQL. The reason behind this is that PostgreSQL’s full-text search capability is best suited for small-scale and straightforward searches. On the other hand, an AI-native database paired with RAG needs to handle various data scales, perform customizable relevance ranking, and especially integrate multiple recalls (including vectors) for fusion ranking. These are tasks that PostgreSQL is not equipped to handle.
How to balance scalability, cost, and other factors?
PostgreSQL is a standalone database. In distributed scenarios, the prevailing approach is to use shard-nothing architecture for scalability. However, vector search and full-text search have distinct constraints and optimization goals, making the use of such complex techniques for scalability unnecessary. As a result, the era of large models calls for a specialized database, rather than a traditional database with added plugins.
Some may consider incorporating vector search capabilities into data lakes as an alternative approach. However, this strategy faces conflicting design objectives. Data lakes traditionally serve offline scenarios where generating complex SQL queries for internal business reports can take a significant amount of time, ranging from minutes to hours. Although there are real-time data lakes from a technical standpoint, they are not specifically designed to handle high concurrency in online scenarios. On the other hand, vector search is commonly used in high-concurrency online business scenarios like search, recommenders, and conversational AI. As a result, there is a disconnect between vector search, which suits high concurrency, and data lakes, which excel at high throughput and low latency, at least in terms of specific use cases.
Therefore, as depicted in the blue box of the diagram, Infinity is a product that integrates AI and data infrastructure. It is specifically designed to cater to online scenarios and fulfill the future requirements of enterprises regarding data infrastructure for large language models.
How about a data lake with vector search capabilities?
Some may consider incorporating vector search capabilities into data lakes as an alternative approach. However, this strategy faces conflicting design objectives. Data lakes traditionally serve offline scenarios where generating complex SQL queries for internal business reports can take a significant amount of time, ranging from minutes to hours. Although there are real-time data lakes from a technical standpoint, they are not specifically designed to handle high concurrency in online scenarios. On the other hand, vector search is commonly used in high-concurrency online business scenarios like search, recommenders, and conversational AI. As a result, there is a disconnect between vector search, which suits high concurrency, and data lakes, which excel at high throughput and low latency, at least in terms of specific use cases.
Therefore, as depicted in the blue box of the diagram, Infinity is a product that integrates AI and data infrastructure. It is specifically designed to cater to online scenarios and fulfill the future requirements of enterprises regarding data infrastructure for large language models.
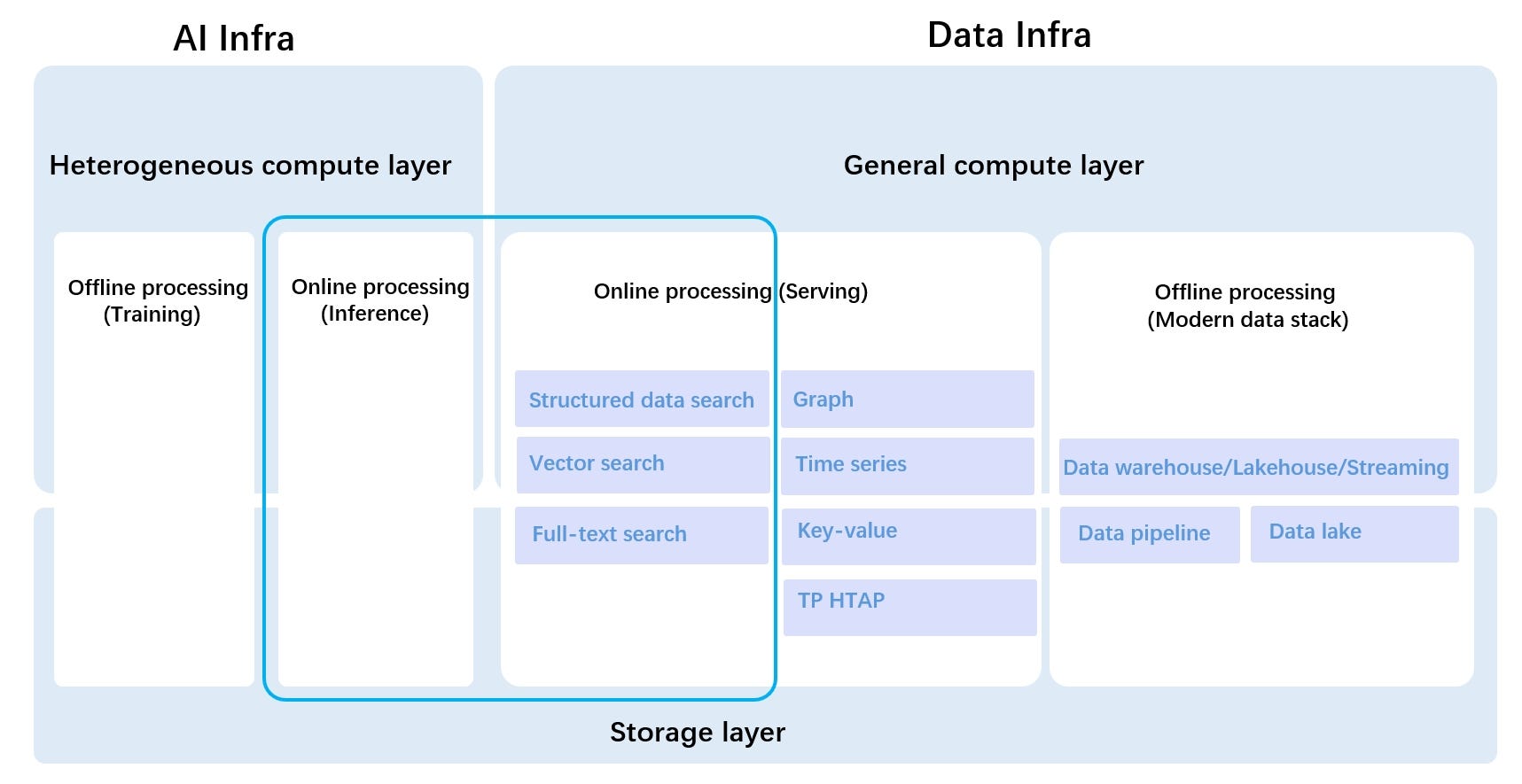
Infinity’s system architecture
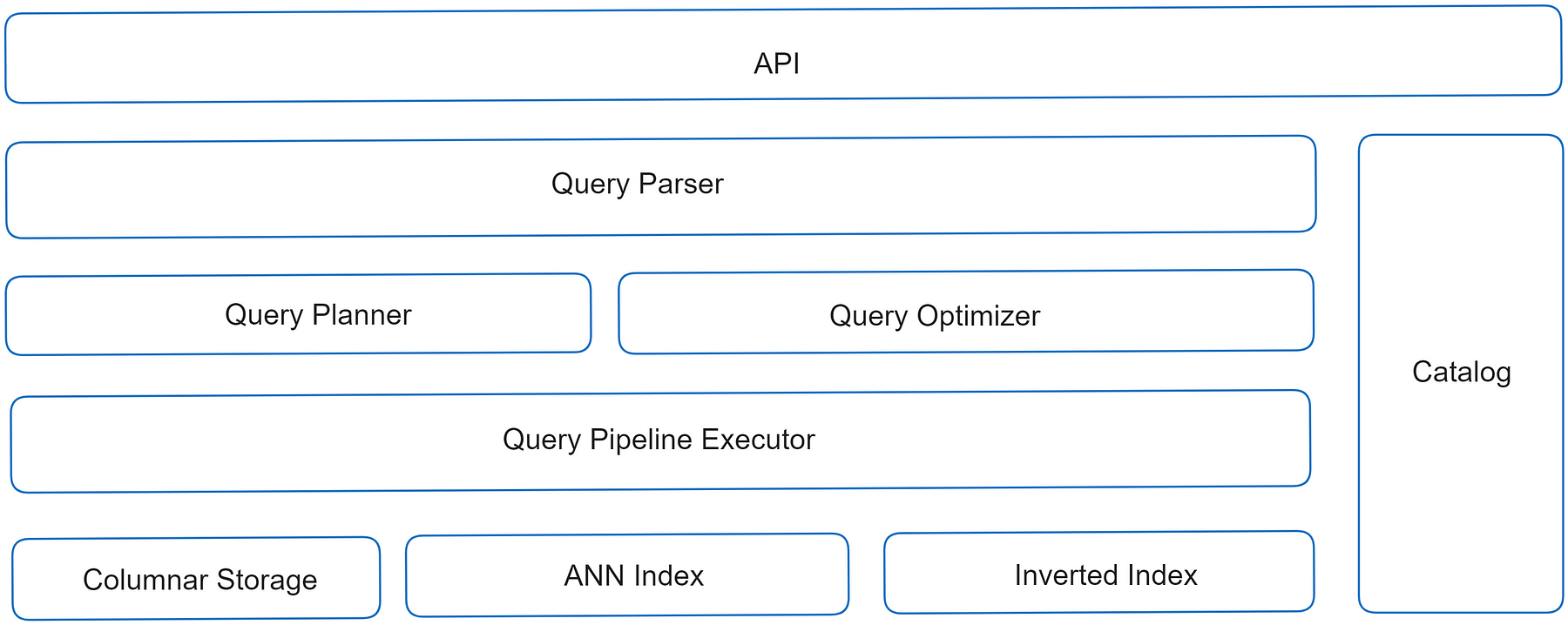
As shown in the diagram above, Infinity consists of two major modules: the storage layer and the computation layer.
Storage Layer
- Columnar Storage: Infinity’s default storage is a columnar storage engine, which focuses on structured data retrieval and guarantees ACID compliance.
- ANN Index (Approximate Nearest Neighbor Index): Infinity utilizes the ANN Index for vector searching. Two types of indexes, IVF and memory-optimized HNSW, are currently available in Infinity. IVF is suitable for memory-constrained scenarios, while HNSW serves high-performance scenarios. In terms of efficiency, Infinity’s HNSW index, employing local quantization techniques, outperforms other vector indexes by providing superior search performance with less memory consumption. Additionally, the ANN index is built on a singular vector-type column in Infinity tables. This allows Infinity to potentially have multiple vector columns, unlike traditional vector databases that can only support one vector column. As a result, Infinity effortlessly enables multi-vector queries.
- Inverted Index: This index caters to both full-text search and structured data retrieval. It comprises two components: a full-text index for text-based searches, which incorporates relevance ranking using BM25 and supports precise recall functionalities like phrase queries, and a secondary index for structured data, delivering efficient filtering capabilities.
Compute Layer
Parser: To assist AI developers, Infinity offers a Pythonic API and a PostgreSQL-compatible SQL dialect, supported by a parser written from scratch. Executor: Infinity’s executor provides a variety of indexes designed for different types of data and data distributions. It dynamically allocates resources, storage options, and queries based on the specific query requirements. For structured queries, it selects either columnar storage or inverted indexes. In low-latency situations, it can use multiple compute units to run queries in parallel. And if there are concerns about concurrency, it can utilize an inverted index on a single compute unit. The choice made by Infinity’s executor is always the best fit for the situation. It follows a push-based pipeline execution plan, which is optimized for handling high volumes of data and concurrent tasks. Infinity’s Fusion operator is responsible for managing multiple recall, sorting and selecting data from vector searches, full-text searches, and structured filtering. This approach prevents inefficiencies and potential errors that may occur when conducting federated search across multiple databases.
Best-in-class vector search performance
Infinity is built with C++20, guaranteeing the best execution paths. It outperforms all existing vector databases in terms of vector search performance, thanks to its innovative algorithms. On an 8-core machine with a dataset of a million SIFT vectors, Infinity effortlessly achieves 10,000 QPS for high-concurrency situations, while in a single-client scenario, the query response latency is as low as 0.1 milliseconds, with minimal memory usage.
In addition, Infinity has integrated C++ Modules to improve development efficiency. This makes it one of the first open-source projects to utilize C++ Modules. As a result, the time required to compile Infinity’s 200,000 lines of code, along with its dependencies amounting to a million lines of C++ code, is significantly reduced. The compilation time is reduced to minutes on a regular personal laptop. This is a great relief for traditional C++ programmers who no longer have to recompile numerous files when modifying a single header file, a process that used to take more than ten minutes. Lastly, we warmly invite you to join the Infinity open-source community and contribute code, which will help accelerate the progress of Infinity towards its GA (general availability).
Our project repo: https://github.com/infiniflow/infinity